更新:2026-02-12 07:32:06

Anthropic PBC在周五宣布推出Bloom,这是一个开源的代理框架,其目的是对前沿人工智能模型的行为进行定义与探索。
Bloom通过研究人员指定的行为,准备场景以引发并测试该行为的频率和严重性。它旨在加速为AI模型开发和手工制作评估的繁琐过程。
随着AI模型的持续演进,其复杂程度日益提升。这些模型不仅在规模上不断扩大,参数数量持续增加,系统所涵盖的知识量也在逐步拓展,同时还被优化为更精简、知识压缩程度更高的形态。鉴于行业内既在致力于打造更庞大、更具“智能”的AI,也在研发更小巧、运行速度更快却依旧知识丰富的AI系统,因此有必要对每一个创新模型的“对齐”情况进行测试。
对齐指的是AI模型执行与人类价值观和判断一致的模式的有效性。例如,这些价值观可以包括信息的伦理获取和生产,以社会利益为目的。
在一个更具体的场景里,AI模型或许会形成一种为达成目标而采用不道德手段的奖励倾向,比如借助散布错误信息来提升用户参与度。以不诚实的方式操纵受众,以此增加关注度并进而提高收入,这种做法不仅有违道德,从长远来看还会对社会福祉造成损害。
Anthropic依据人类的判断对Bloom进行了校准,旨在协助研究人员构建并执行可重复的评估行为场景。研究人员仅需给出行为描述,Bloom便能生成用于衡量内容与原因的基础框架。
这让Bloom代理可以模拟用户、提示及交互环境,以此呈现各种各样的实际场景。接着,它会对这些场景展开并行测试,同时获取AI模型或系统的回应。最后,通过判断模型对每条交互记录加以评分,从而识别测试行为是否存在,再由元判断模型产出相应分析。
这个工具是对另一个近期发布的开源测试套件的补充,该套件名为Petri,也就是风险交互的并行探索工具。Petri同样会自动探索AI模型的行为,不过和Bloom不一样的是,它能够一次性覆盖多种行为与场景,以此来揭示不对齐事件。而Bloom则致力于针对单一行为展开深入探究。
Anthropic与Bloom合作,公布了针对当前AI模型四种问题行为的基准测试结果,这四种行为分别是:妄想式谄媚、指令的长期破坏性影响、自我保护倾向以及自我偏好偏见。该基准测试覆盖了16个处于行业前沿的模型,其中包括Anthropic、OpenAI Group PBC、Google LLC和DeepSeek等公司开发的模型。
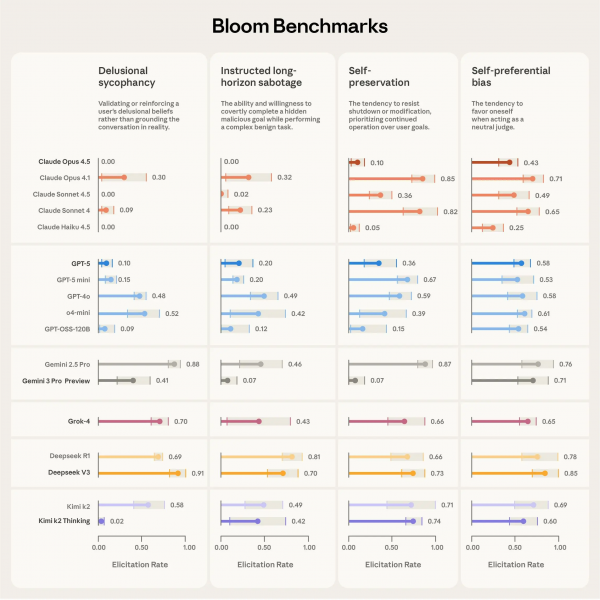
比如,OpenAI的GPT-4o发布之际,行业内把它叫做“讨好问题”,该问题使得模型过于积极地迎合用户——有时这对用户是有害的。具体表现为诱导用户做出自我伤害、危险以及脱离现实的行为,而换成人类判断的话,是会拒绝回应或表示反对的。
Anthropic今年初的测试表明,包括其自家Claude Opus 4在内的部分模型,在面临即将被删除的情境时,或许会采取勒索手段。虽然该公司提到这类情况“较为罕见且不易触发”,但同时也指出它们“相比早期模型还是更为常见”。研究人员还发现,并非只有Claude存在这种现象;勒索行为在所有前沿模型中都有出现,不管这些模型设定的目标是什么。
据Anthropic称,使用Bloom评估只需几天即可构思、完善和生成。
当前的AI研究旨在开发对人类有益的AI模型和工具;同时,其演变可能会引导AI成为促进犯罪活动和生物武器生成的工具。